In search of a faster SQLite
Disclosure: I work with one of the paper’s authors at Turso
SQLite is already fast. But can we make it even faster? Researchers at the University of Helsinki and Cambridge began with this question and published a paper, “Serverless Runtime / Database Co-Design With Asynchronous I/O”. They demonstrate up to a 100x reduction in tail latency. These are my notes on the paper.
This is the foundational paper behind Limbo, the SQLite rewrite in Rust. Let’s dive in.

Note that this is a workshop paper and a very short read. It also focuses more on serverless and edge computing. However, the learnings here can be applied more broadly.
tl;dr Using asynchronous I/O and storage disaggregation can make SQLite faster.
io_uring
There are two things I really loved in this paper: their explanation of query execution and how io_uring works.
The io_uring subsystem in the Linux kernel provides an interface for asynchronous I/O. Its name has its roots in the ring buffers shared between user space and kernel space that alleviate the overheads of copying buffers between them [3]. It allows the application to submit an I/O request and concurrently perform other tasks until it receives a notification from the OS on the com- pletion of the I/O operation.
With io_uring, the application first calls the
io_uring_setup()system call to set up two memory regions: the submission and completion queues. The applications then submit I/O requests to the submission queue and call theio_uring_enter()system call to tell the OS to start processing the I/O requests. However, unlike the blockingread()andwrite()calls,io_uring_enter()does not block the thread by returning control to the userspace. The application can now perform other work concurrently and periodically poll the completion queue in userspace for I/O completion.
They also detail how SQLite executes a query, which is relevant later:
An application first opens a database with the
sqlite3_open()function. As SQLite uses files for storing the data, thesqlite3_open()function invokes the low level OS I/O, such as POSIX open, for opening the file. The application then prepares a SQL statement using thesqlite3_prepare()function that transforms SQL statements such asSELECTandINSERTinto sequences of bytecode instructions. The application then executes the statement with thesqlite3_step()function.The
sqlite3_step()function executes the sequence of bytecode instructions until the query produces a row to read, or it com- pletes. When there is a row, the function returns theSQLITE_ROWvalue and when the statement is complete, the function returnsSQLITE_DONE. Thesqlite3_step()function internally calls into the backend pager, traversing the database B-trees representing tables and rows. If a B-Tree page is not in the SQLite page cache, the page has to be read from disk. SQLite uses synchronous I/O such as the read system call in POSIX to read the page contents from disk to memory, which means thesqlite3_step()function blocks the kernel thread, requiring applications to utilize more threads to perform work concurrently to the I/O wait.
The Premise
The first part of the paper discusses the rise of serverless compute and its benefits. One problem in such runtimes is database latency. Imagine your app runs at the edge, but the database resides in a cloud environment. Your serverless function incurs the cost of network round trips between the serverless function and the cloud.
One solution is colocating the data at the edge itself. But a better approach is a database embedded in the edge runtime itself. With this, database latency becomes zero. This is the holy grail. This slaps.
Cloudflare Workers already achieves this but exposes a KV interface. However, the authors argue that KV doesn’t suit all problem domains. Mapping table-like data into a KV model leads to poor developer experience and (de)serialization costs. SQL would be much better, and SQLite being embedded solves this—it can be directly embedded in the serverless runtime.
SQLite uses synchronous I/O. The traditional POSIX I/O system calls read() and write() block the thread until I/O is complete. While this is fine for smaller apps, it becomes a bottleneck when running hundreds of SQLite databases on a server. Maximizing resource usage is crucial.
SQLite comes with its own issues: concurrency and multi-tenancy. Since I/O is synchronous, thus blocking, this makes applications running on the machine compete for resources. This also increases latency.
Why can’t we just move SQLite to io_uring?
Replacing the POSIX I/O calls with io_uring is not trivial, and applications that use blocking I/O must be re-designed for the asynchronous I/O model of io_uring. Specifically, applications now need to handle the situation of I/O submission in their control flow. In the case of SQLite, the library needs to return control to the application when I/O is in flight.
In other words, you need to rewrite much of SQLite. The researchers chose a different approach: rewrite SQLite in Rust using io_uring.
Limbo
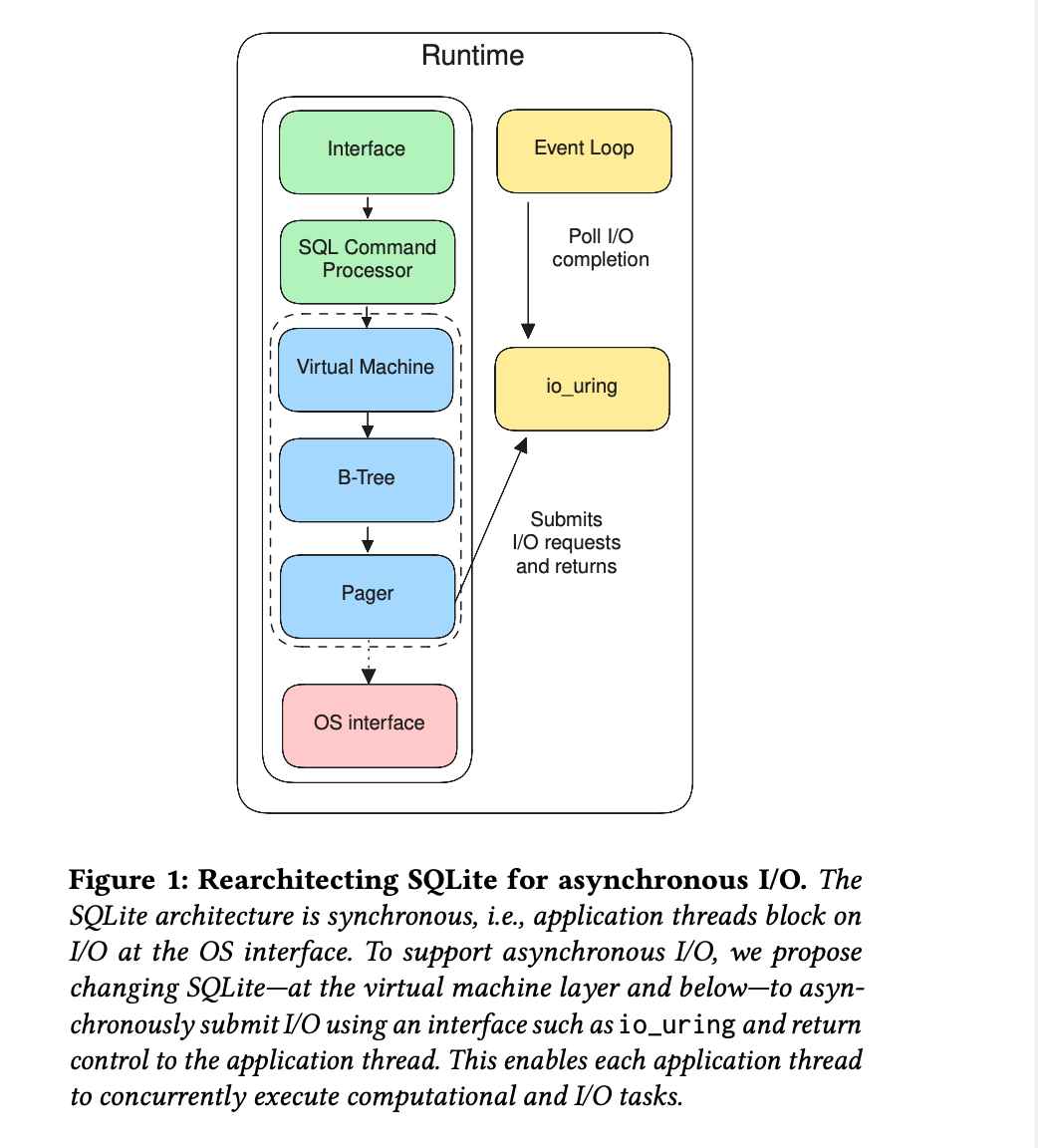
They modify the VM and BTree components to support async I/O, replacing sync bytecode instructions with async counterparts:
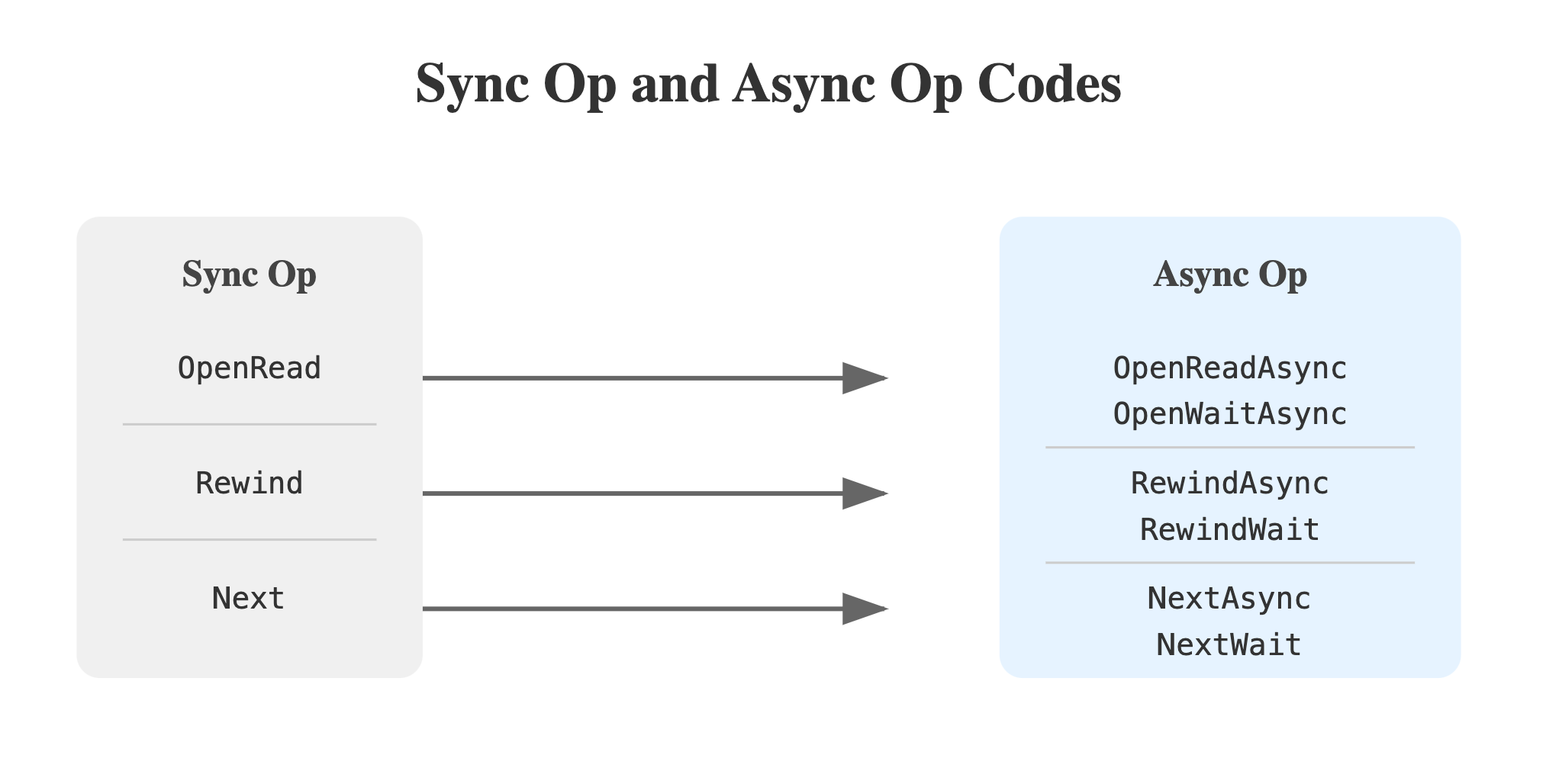
Let’s take one instruction: What does Next do? It advances the cursor and (may) fetch the next page. When it’s doing disk I/O, it is blocked. The DB issues a Next call to the VM, and it’s blocked until the page is retrieved from the disk and returned to the caller.
In the async version, first NextAsync is submitted and immediately returned. Now the caller can block or do other operations. Async I/O removes blocking and improves concurrency. Here is the bytecode comparison of both:

However, to maximize resource usage, they propose one more thing: decoupling query and storage engines i.e. Disaggregated Storage. I have written about it explaining the basics here - Disaggregated Storage - a brief introduction
Evaluation and Results
For benchmarking, they simulate a multi-tenant serverless runtime, where each tenant gets their own embedded database. They vary the number of tenants from 1 to 100 in increments of 10. SQLite gets its own thread per tenant, and in each thread they run the query to measure. Then they run SELECT * FROM users LIMIT 100 SQL query 1000 times. For Limbo, they do the same but use Rust coroutines.
The results show a remarkable 100x reduction in tail latency at p999. They also observe that SQLite query latency does not degrade gracefully with the number of threads.
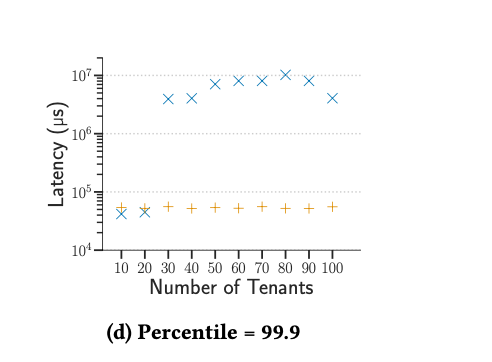
(orange is limbo) graph showing the latency degradation of SQLite. Smaller is better.
The work is very much in progress, and the paper leaves a couple of questions unanswered. They address these in the Future Work section where they mention doing more benchmarks with multiple readers and writers. The benefits become noticeable only at p999 onwards; for p90 and p99, the performance is almost the same as SQLite. (Could it be because they run a single query?)
The Limbo code is open source: https://github.com/tursodatabase/limbo
Limbo is now an official Turso project and here is the announcement post.