Recurse Center Day 2: BTree Node
This is a draft post that I have prematurely published. Currently, I am attending RC and I want to write as much as possible, log my daily learnings and activities. But, I also don't want to spend time on grammar and prose, so I am publishing all the posts which usually I'd have kept in my draft folder.
B Tree
I started working on the B Tree project, created a Github repo, put up skeleton code. Then I started wondering how best would I represent a B Tree node in code.
In B Tree, I need to maintain a sorted array of keys (think primary keys) in a node:
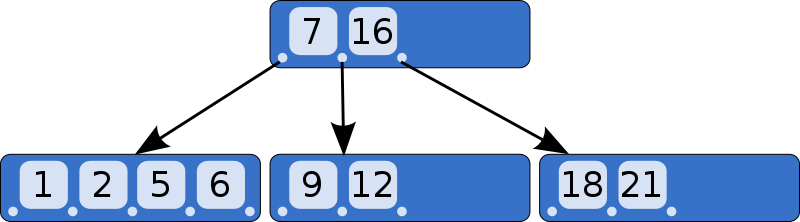
Left of each key’s child will be arrays containing less than of that key and right would be more than of key. In the above diagram, we have four nodes in total. If a node has 4 keys, at max there would be 5 pointers. My question was how would you represent one node?
One idea which immediately came to my mind was storing a struct that contains both the pointers, in an array:
[(7, *1, *9), (16, *9, *18)]
// *1 is the pointer to the left most leaf array
Another idea was to maintain two separate arrays, wherein one holds the keys and in another just the pointers.
keys [7, 16]
child: [*1, *9, *18]
I started thinking about the pros and cons of both approaches:
First one: Easy to code, inserting an item is straight forward but this one takes way more space.
Second one: Insertion is slightly trickier, if I want to insert something, I need to find the slot in the first array and then move the pointers accordingly in the second.
I found out the most academic references use the first approach and the practical ones use the second one. e.g.: google/btree, rust/btreemap
People
RC experience is all about meeting people, learning and sharing ideas. Today I met two interesting people
Elvis is learning elixir and plans to build an interesting analytics engine using the phoenix framework. Today we paired to work on his project. I don’t know elixir at all, but Elvis was kind enough to teach me the language basics and walk me through the code.
He taught me about Agent, GenServer, really cool pattern matching features. I am looking forward to learning more about elixir.
I also spoke with Yoshi today, who is an alumn who built a disk-based database using LSM Tree in Rust. We discussed the challenges and shared notes.
LSM Challenges: locks, concurrent writes, copy on write etc.